
在上一篇中,我们讲了存储节点上的盘的划分,请参考Exadata的数据保护机制(冗余机制)- 1
那么这次我们来说说,在Exadata上有ASM哪些不同于传统架构(非Exadata环境)的特点,他是怎么保护数据的。
首先我们来回顾一下ASM的相关知识点
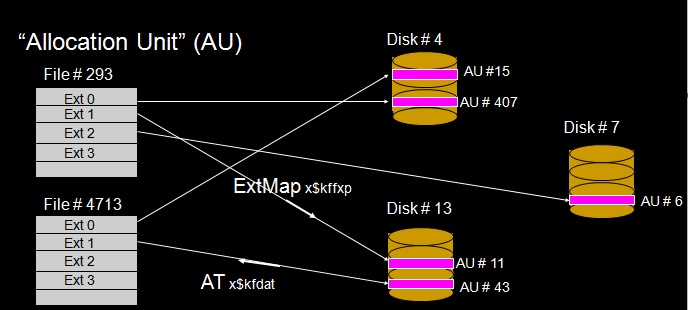
我们知道,就像数据库文件从逻辑上分为很多extents一样(每个segment由多个extents组成),ASM的文件(ASM FILE)也分为很多extent(ASM FILE EXTENTS)。也就是说,数据库中datafile包含的逻辑存储单元是segment,extent等等,而ASM上ASMFILE的逻辑存储单元是asmfile extent。
数据库文件的物理单元是block,而ASM文件的物理单元是AU。
因此,我们知道了,每个ASM file包含很多extent,ASM FILE和extent之间对应关系就是 EXTENT MAP(每个asmfile上extents的分布)
每个物理磁盘包含很多AU,磁盘和AU之间的对应关系就在ALLOCATION TABLE中(每个磁盘上AU的分布)。
ASM的镜像是基于文件extent的粒度,extent分布在多个磁盘之间,称为partner。Partner disk会存放在一个或者多个分离的failure group上。
在ASM中,每个文件都按照AU的尺寸打散到磁盘组中所有的磁盘上,我们把这种条带划叫做粗糙条带划(COARSE striping),粗糙条带划是根据AU的尺寸的(即,缺省为1M,Exadata上通常为4M)。对于控制文件的条带划,是采用128k的Striping的,称之为“Fine striping”。
AU的缺省尺寸是1M,ASM的block缺省大小是4k,这其实是受隐含参数控制的:
_asm_blksize 4096 metadata block size
_asm_ausize 1048576 allocation unit size
在Exadata上缺省的AU为4M(推荐值),ASM block为4k。
查询各种文件条带划的信息(下面是在我的Exadata VM上测试的输出):
SQL> select distinct name,stripe from v$asm_template;
NAME STRIPE ------------------------------ ------ ARCHIVELOG COARSE ASMPARAMETERFILE COARSE AUTOBACKUP COARSE BACKUPSET COARSE CHANGETRACKING COARSE CONTROLFILE FINE ------只有控制文件是按照128k进行条带划的 DATAFILE COARSE DATAGUARDCONFIG COARSE DUMPSET COARSE FLASHBACK COARSE FLASHFILE COARSE OCRFILE COARSE ONLINELOG COARSE PARAMETERFILE COARSE TEMPFILE COARSE XTRANSPORT COARSE 16 rows selected. SQL>
在 Exadata 上, ASM Diskgroup 是按照 Normal Redundancy 创建的(可以选择 High Redundancy来选择,但是这样选择的客户很少)。
因此,每个AU采用双份Fail Group的保护方式,也就是说,数据将会同时在两个Failgroup中个存有一个副本。
而在上一节中《Exadata的数据保护机制(冗余机制)- 1 》 ,我们已经讨论了不同的Failgroup一定不会来自于同一个Storage Cell。
这样就确保了不论是一块磁盘损坏还是有整个Storage Cell损坏都不会丢失数据。ASM镜像的原理请参见官方的解释:

综上,在10g中,每盘都会存在最多10个Disk partner,而在11gR2中每盘都会存在最多8个Disk partner。
(它是受到隐含参数”_asm_partner_target_disk_part”控制的)。
因此,在re-balance过程中,如果再次发生磁盘的故障,必须故障磁盘是和原有损坏磁盘有partner关系的有限数量的磁盘(Exadata上是小于8块盘)才可能发生数据丢失的情况。每个cell上12块盘,一个1/4 Rack也有36块盘(36块盘分别是36个celldisk,然后每个celldisk上划分一块空间创建了griddisk,缺省创建3个前缀的griddisk(DATA_,RECO_,DBFS_),共108个griddisk,创建ASM磁盘组的时候,从来自于3个cell的108个griddisk中那盘…………太罗嗦了,不说了),因此,这个概率是很小的。
当发生了一块磁盘损坏的情况下,由于这个磁盘在其他Failgroup上有镜像数据,ASM将控制其他可用的Failgroup(没有损坏的)进行Reblance操作。
这么做的意义,主要是为了将丢失了保护的数据(单份数据)再次实现跨Failgroup的重新分布,从而,确保在Reblance结束后,该数据在其他没有损坏的盘上再次构建了Normal Redundancy的保护(即,又有两份数据来保护了)。
需要注意的是,一个磁盘并不会和不在同一个Failgroup的其他所有磁盘构成partner disk关系。
检查group#=1号 disk#=0号磁盘的partner关系:
[grid@dm01db01 ~]$ sqlplus /nolog
SQL*Plus: Release 11.2.0.3.0 Production on Thu Mar 31 16:05:17 2012
Copyright (c) 1982, 2010, Oracle. All rights reserved.
SQL> connect / as sysasm;
Connected.
SQL> select p.number_kfdpartner,d.failgroup
2 from x$kfdpartner p,v$asm_disk d
3 where p.disk=0
4 and p.grp=1
5 and p.grp=group_number
6 and p.number_kfdpartner=d.disk_number;
NUMBER_KFDPARTNER FAILGROUP
—————– ——————————
167 DM01CEL01
165 DM01CEL01
15 DM01CEL03
33 DM01CEL04
23 DM01CEL03
26 DM01CEL04
151 DM01CEL14
150 DM01CEL14
8 rows selected.
SQL>
这里我们看到,这是一个满配的Exadata,这块盘(group#1, disk#0)的数据镜像分布在其它8块partner disk中(参见《Doc ID 1086199.1》(10g中是10块,11.2以后是8块),其partner disk分别在4个cell上(cell1, cell3, cell4, cell14)的8个磁盘上。
因此,在re-balance过程中,如果再次发生磁盘的故障,必须故障磁盘是和原有损坏磁盘有partner关系的有限数量的磁盘(小于10块盘)才可能发生数据丢失的情况。
可见,这个数据丢失的概率是非常小的(满配的 Exadata 上,14*12=168块盘)。
在更加恶劣的情况下,例如一个Storage Cell损坏,也不会导致数据丢失。ASM会控制位于剩余的Storage Cell的Failgroup对这时候没保护的数据进行重分布,当然,前提是你还有多余的空间让他做Reblance操作。
如果这个由于这个cell损坏,系统在做Rebalance时,再坏了一个Cell会怎么样呢?
当你明白了上面的原理,这个我不说你也知道了,O(∩_∩)O哈哈~
答案: 分两种情况。





