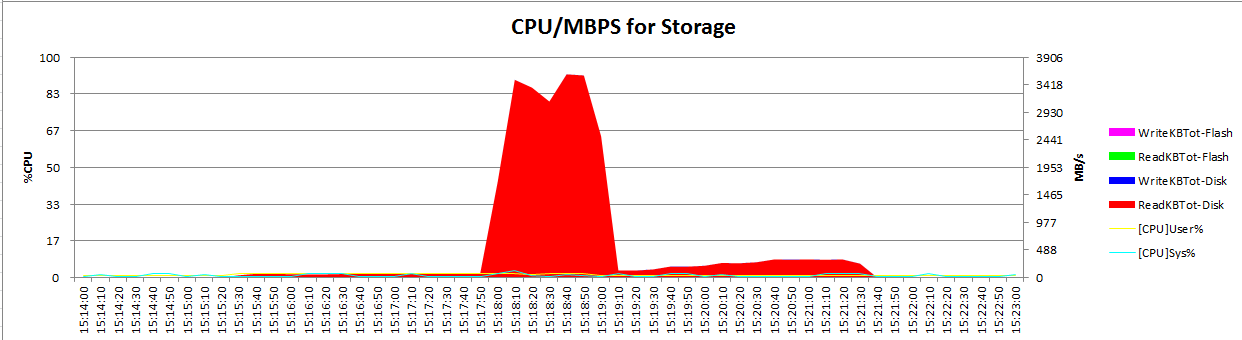
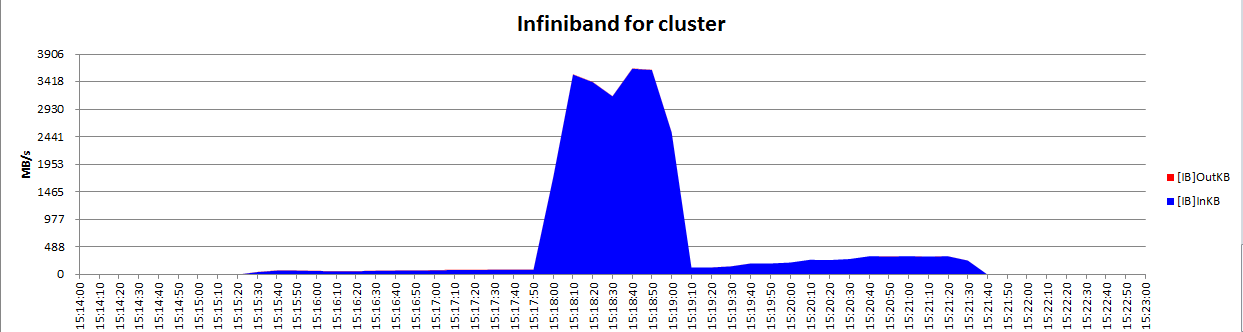
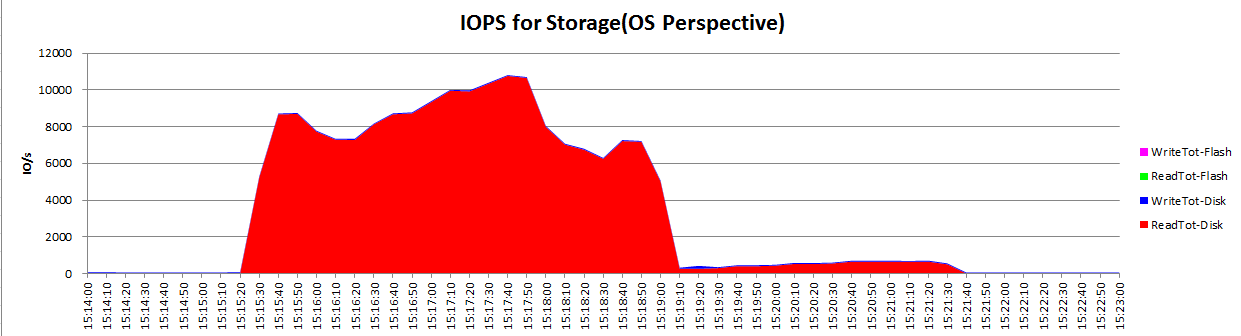
Oracle Clusterware使用oifcfg来管理网络信息(网卡,子网,网络接口的角色等等),但是他不管理每个网卡实际的IP地址。
因此,不能使用oifcfg来修改IP地址(只能修改子网)。
可以使用oifcfg getif来显示当前OCR里面的网卡信息,例如:
[root@RAC1 ~]# which oifcfg /u01/11.2.0/grid/bin/oifcfg [root@RAC1 ~]# env|grep ORA ORACLE_SID=+ASM1 ORACLE_BASE=/u01/app/grid ORACLE_HOME=/u01/11.2.0/grid [root@RAC1 ~]# [root@RAC1 ~]# oifcfg getif eth0 192.168.56.0 global public eth1 192.168.88.0 global cluster_interconnect [root@RAC1 ~]#
在UNIX和linux系统中,网络接口的名称通常由OS来分配。
Windows系统中有所不同(不熟悉Windows上的RAC,职业生涯中,安装不超过10次Windows平台的RAC……)
数据库对外提供服务的网络,我们通常称为PUBLIC网络,VIP也是存储在OCR里面跟PUBLIC同一网段上的IP地址
注意:VIP是绑定在public ip上的虚拟IP,只有CRS启动后,才有VIP。
用于RAC中节点间通信或者RDBMS跟ASM实例通信的网络,我们称之为Private网络(私有网络),用于内部互联。
从11.2开始,cluster_interconnect也被用来做clusterware hearbeats
在11.2之前(11.1和10g),RACA使用私有IP对应的主机名(例如 lunar-priv)来作为集群的心跳(在安装RAC时有界面让指定的)
.
当修改了私有网络的IP或者主机名,就需要修改CRS(10g和11.1)或者GI(11.2以后)。
8i和9i没这个问题,因为那时候,Oracle没有自己的集群软件,只有“集群数据库”,所有的集群功能都是第三方集群软件完成的。
例如 :
HP的MC SERVERS GUARD/OPS OPTION
AIX的HACMP
Solaris的SUN Cluster
Tru64 UNIX的TruCluster
………………
.
在11.2之前,私有IP对应的主机名保存在OCR中,我们不能修改私有网络的主机名。
但是正因为如此,修改了私有IP,而私有IP对应的主机名其实并没有发生改变。
如果要修改主机名就简单的执行rootdelete.sh和rootdeinstall.sh重新配置CRS就可以了。
具体的例子请参考《在10.2 RAC中重建CRS的过程》
.
从11.2开始,CRS(Cluster Ready Service)升级为GI(Grid Infrastructure)。
私有IP对应的私有主机名不再存储在OCR中了(通过GNPN架构来管理,即 网络即插即用,后面会讲)。
OCR和私有IP对应的主机名也不再有依赖关系。可以随便修改/etc/hosts
例如这里,
我们把两个节点的私有IP的主机名都修改一下:
RAC1-priv都修改为lunar1-priv
RAC2-priv修改为lunar2-priv
[root@RAC1 ~]# cat /etc/hosts # Do not remove the following line, or various programs # that require network functionality will fail. 127.0.0.1 localhost.localdomain localhost ::1 localhost6.localdomain6 localhost6 #rac1 192.168.56.81 rac1.localdomain rac1 192.168.56.85 rac1-vip.localdomain rac1-vip 192.168.88.81 lunar1-priv.localdomain lunar1-priv #rac2 192.168.56.82 rac2.localdomain rac2 192.168.56.86 rac2-vip.localdomain rac2-vip 192.168.88.82 lunar2-priv.localdomain lunar2-priv #scan-ip 192.168.56.88 scan 10.10.10.66 s-dg 10.10.10.11 r-dg1 10.10.10.12 r-dg2 10.10.10.21 r-dg1-vip 10.10.10.22 r-dg2-vip [root@RAC1 ~]#
关闭CRS:
[root@RAC1 ~]# crsctl stop crs -f CRS-2791: Starting shutdown of Oracle High Availability Services-managed resources on 'rac1' CRS-2673: Attempting to stop 'ora.crsd' on 'rac1' CRS-2790: Starting shutdown of Cluster Ready Services-managed resources on 'rac1' CRS-2673: Attempting to stop 'ora.LISTENER.lsnr' on 'rac1' CRS-2673: Attempting to stop 'ora.LISTENER_SCAN1.lsnr' on 'rac1' CRS-2673: Attempting to stop 'ora.racdb.db' on 'rac1' CRS-2673: Attempting to stop 'ora.oc4j' on 'rac1' CRS-2673: Attempting to stop 'ora.cvu' on 'rac1' CRS-2677: Stop of 'ora.LISTENER.lsnr' on 'rac1' succeeded CRS-2673: Attempting to stop 'ora.rac1.vip' on 'rac1' CRS-2677: Stop of 'ora.LISTENER_SCAN1.lsnr' on 'rac1' succeeded CRS-2673: Attempting to stop 'ora.scan1.vip' on 'rac1' CRS-2677: Stop of 'ora.rac1.vip' on 'rac1' succeeded CRS-2672: Attempting to start 'ora.rac1.vip' on 'rac2' CRS-2677: Stop of 'ora.scan1.vip' on 'rac1' succeeded CRS-2672: Attempting to start 'ora.scan1.vip' on 'rac2' CRS-2677: Stop of 'ora.racdb.db' on 'rac1' succeeded CRS-2673: Attempting to stop 'ora.ASMDATA.dg' on 'rac1' CRS-2673: Attempting to stop 'ora.DATA.dg' on 'rac1' CRS-2676: Start of 'ora.scan1.vip' on 'rac2' succeeded CRS-2676: Start of 'ora.rac1.vip' on 'rac2' succeeded CRS-2672: Attempting to start 'ora.LISTENER_SCAN1.lsnr' on 'rac2' CRS-2676: Start of 'ora.LISTENER_SCAN1.lsnr' on 'rac2' succeeded CRS-2677: Stop of 'ora.ASMDATA.dg' on 'rac1' succeeded CRS-2677: Stop of 'ora.oc4j' on 'rac1' succeeded CRS-2672: Attempting to start 'ora.oc4j' on 'rac2' CRS-2677: Stop of 'ora.cvu' on 'rac1' succeeded CRS-2672: Attempting to start 'ora.cvu' on 'rac2' CRS-2676: Start of 'ora.cvu' on 'rac2' succeeded CRS-2677: Stop of 'ora.DATA.dg' on 'rac1' succeeded CRS-2673: Attempting to stop 'ora.asm' on 'rac1' CRS-2677: Stop of 'ora.asm' on 'rac1' succeeded CRS-2676: Start of 'ora.oc4j' on 'rac2' succeeded CRS-2673: Attempting to stop 'ora.ons' on 'rac1' CRS-2677: Stop of 'ora.ons' on 'rac1' succeeded CRS-2673: Attempting to stop 'ora.net1.network' on 'rac1' CRS-2677: Stop of 'ora.net1.network' on 'rac1' succeeded CRS-2792: Shutdown of Cluster Ready Services-managed resources on 'rac1' has completed CRS-2677: Stop of 'ora.crsd' on 'rac1' succeeded CRS-2673: Attempting to stop 'ora.ctssd' on 'rac1' CRS-2673: Attempting to stop 'ora.evmd' on 'rac1' CRS-2673: Attempting to stop 'ora.asm' on 'rac1' CRS-2673: Attempting to stop 'ora.mdnsd' on 'rac1' CRS-2677: Stop of 'ora.evmd' on 'rac1' succeeded CRS-2677: Stop of 'ora.mdnsd' on 'rac1' succeeded CRS-2677: Stop of 'ora.ctssd' on 'rac1' succeeded CRS-2677: Stop of 'ora.asm' on 'rac1' succeeded CRS-2673: Attempting to stop 'ora.cluster_interconnect.haip' on 'rac1' CRS-2677: Stop of 'ora.cluster_interconnect.haip' on 'rac1' succeeded CRS-2673: Attempting to stop 'ora.cssd' on 'rac1' CRS-2677: Stop of 'ora.cssd' on 'rac1' succeeded CRS-2673: Attempting to stop 'ora.crf' on 'rac1' CRS-2677: Stop of 'ora.crf' on 'rac1' succeeded CRS-2673: Attempting to stop 'ora.gipcd' on 'rac1' CRS-2677: Stop of 'ora.gipcd' on 'rac1' succeeded CRS-2673: Attempting to stop 'ora.gpnpd' on 'rac1' CRS-2677: Stop of 'ora.gpnpd' on 'rac1' succeeded CRS-2793: Shutdown of Oracle High Availability Services-managed resources on 'rac1' has completed CRS-4133: Oracle High Availability Services has been stopped. [root@RAC1 ~]#
在OS层修改私有网络的IP地址和私有网络对应的主机名。
然后,直接重启CRS:
[root@RAC1 ~]# crsctl start crs CRS-4123: Oracle High Availability Services has been started. [root@RAC1 ~]#
看节点1的crs正常启动,没有问题(oc4j启动很慢,这个不用管):
节点2我down了,没有启动,因此只显示了节点1的
而且,这里面dg单独配置了一个网卡,我也调整了,后面会说,怎么把ADG专有的network2修复好。
[root@RAC1 ~]# crsctl status res -t
--------------------------------------------------------------------------------
NAME TARGET STATE SERVER STATE_DETAILS
--------------------------------------------------------------------------------
Local Resources
--------------------------------------------------------------------------------
ora.ASMDATA.dg
ONLINE ONLINE rac1
ora.DATA.dg
ONLINE ONLINE rac1
ora.LISTENER.lsnr
ONLINE ONLINE rac1
ora.LISTENER_DG.lsnr
ONLINE OFFLINE rac1
ora.asm
ONLINE ONLINE rac1 Started
ora.gsd
OFFLINE OFFLINE rac1
ora.net1.network
ONLINE ONLINE rac1
ora.net2.network
ONLINE OFFLINE rac1
ora.ons
ONLINE ONLINE rac1
--------------------------------------------------------------------------------
Cluster Resources
--------------------------------------------------------------------------------
ora.LISTENER_SCAN1.lsnr
1 ONLINE ONLINE rac1
ora.cvu
1 ONLINE ONLINE rac1
ora.oc4j
1 ONLINE OFFLINE STARTING
ora.r-dg1-vip.vip
1 ONLINE OFFLINE
ora.r-dg2-vip.vip
1 ONLINE OFFLINE
ora.rac1.vip
1 ONLINE ONLINE rac1
ora.rac2.vip
1 ONLINE INTERMEDIATE rac1 FAILED OVER
ora.racdb.db
1 ONLINE ONLINE rac1 Open
2 ONLINE OFFLINE
ora.scan1.vip
1 ONLINE ONLINE rac1
[root@RAC1 ~]#