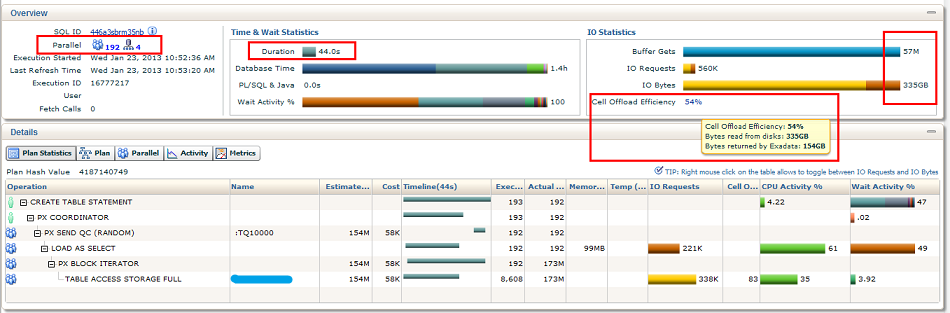
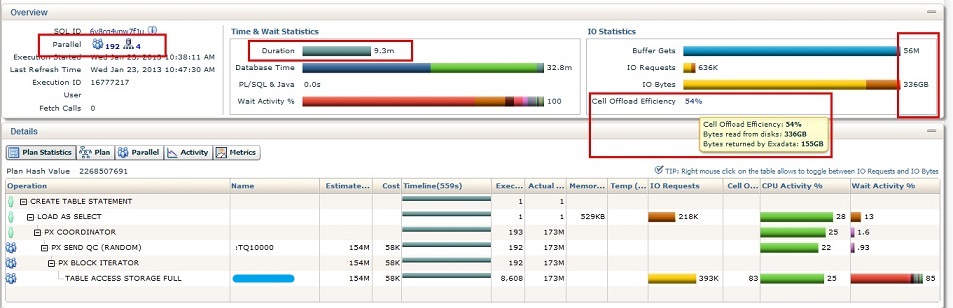
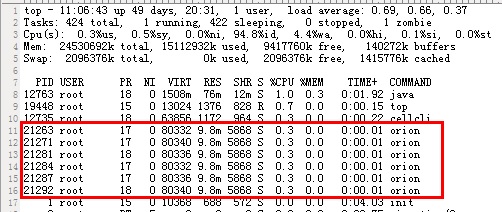
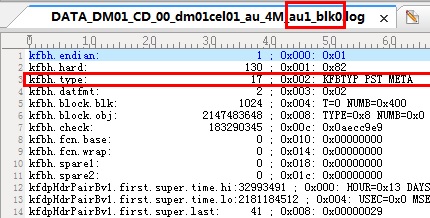
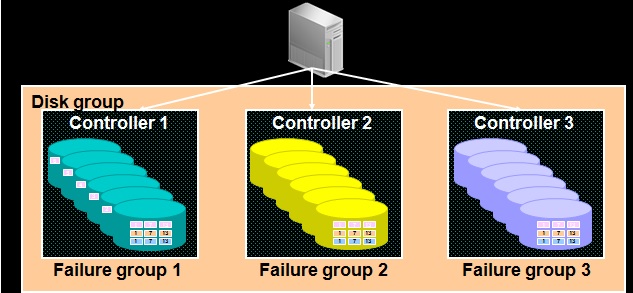
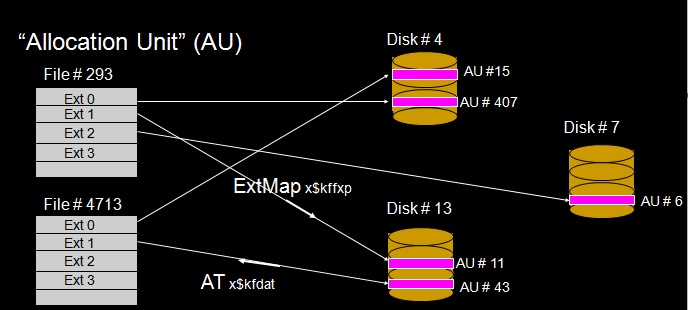
- DBNAME
- MOUNT_POINT
- DBFS_USER
- ORACLE_HOME (should be the RDBMS ORACLE_HOME directory)
- NOHUP_LOG (used only if WALLET=false)
- DBFS_PASSWD (used only if WALLET=false)
- DBFS_PWDFILE (used only if WALET=false)
- WALLET (must be true or false)
- TNS_ADMIN (used only if WALLET=true)
# cat mount-dbfs.sh
#!/bin/bash
### This script is from Note 1054431.1, ensure you have the latest version
### Note 1054431.1 provides information about the setup required to use this script
### updated 22-MAR-2011
###########################################
### Everyone must set these values
###########################################
### Database name for the DBFS repository as used in “srvctl status database -d $DBNAME”
DBNAME=lunar3
### Mount point where DBFS should be mounted
MOUNT_POINT=/dbfsmnt
### Username of the DBFS repository owner in database $DBNAME
DBFS_USER=dbfs_user
### RDBMS ORACLE_HOME directory path
ORACLE_HOME=/u01/app/oracle/product/11.2.0/dbhome_1
### Full path to a logfile (or /dev/null) for output from dbfs_client’s nohup
### Useful for debugging, normally use /dev/null
NOHUP_LOG=/dev/null
### Syslog facility name (default local3)
### This is only needed if you want to capture debug outputs using syslog
LOGGER_FACILITY=local3
###########################################
### If using password-based authentication, set these
###########################################
### This is the plain text password for the DBFS_USER user
DBFS_PASSWD=dbfs_passwd
### The file used to temporarily store the DBFS_PASSWD so dbfs_client can read it
### This file is removed immediately after it is read by dbfs_client
DBFS_PWDFILE=/home/oracle/.dbfs-passwd.txt
### mount options for dbfs_client
MOUNT_OPTIONS=allow_other,direct_io
###########################################
### If using wallet-based authentication, modify these
###########################################
### WALLET should be true if using a wallet, otherwise, false
WALLET=false
### TNS_ADMIN is the directory containing tnsnames.ora and sqlnet.ora used by DBFS
TNS_ADMIN=/home/oracle/dbfs/tnsadmin
### mount options for wallet-based mounts are in /etc/fstab
###########################################
### No editing is required below this point
###########################################
MOUNT=/bin/mount
GREP=/bin/grep
AWK=/bin/awk
XARGS=’/usr/bin/xargs -r’
ECHO=/bin/echo
LOGGER=’/bin/logger -t DBFS’
RMF=’/bin/rm -f’
PS=/bin/ps
SLEEP=/bin/sleep
KILL=/bin/kill
READLINK=/usr/bin/readlink
BASENAME=/bin/basename
FUSERMOUNT=/bin/fusermount
ID=/usr/bin/id
SRVCTL=$ORACLE_HOME/bin/srvctl
DBFS_CLIENT=$ORACLE_HOME/bin/dbfs_client
HN=/bin/hostname
LD_LIBRARY_PATH=$ORACLE_HOME/lib:/lib64
export ORACLE_HOME LD_LIBRARY_PATH TNS_ADMIN
export PATH=$ORACLE_HOME/bin:$PATH
logit () {
### type: info, error, debug
type=$1
msg=$2
if [ “$type” = “info” ]; then
$ECHO $msg
$LOGGER -p ${LOGGER_FACILITY}.info $msg
elif [ “$type” = “error” ]; then
$ECHO $msg
$LOGGER -p ${LOGGER_FACILITY}.error $msg
elif [ “$type” = “debug” ]; then
$ECHO $msg
$LOGGER -p ${LOGGER_FACILITY}.debug $msg
fi
}
### must not be root
if [ `$ID -u` -eq 0 ]; then
logit error “Run this as the Oracle software owner, not root”
exit 1
fi
### determine how we were called, derive location
SCRIPTPATH=`$READLINK -f $0`
SCRIPTNAME=`$BASENAME $SCRIPTPATH`
### must cd to a directory where the oracle owner can get CWD
cd /tmp
case “$1” in
‘start’)
logit info “$SCRIPTNAME mounting DBFS at $MOUNT_POINT from database $DBNAME”
### check to see if it is already mounted
$SCRIPTPATH status > /dev/null 2>&1
if [ $? -eq 0 ]; then
logit error “$MOUNT_POINT already mounted, use \”$SCRIPTNAME stop\” “\
“before attempting to start”
$SCRIPTPATH status
exit 1
fi
### set the ORACLE_SID dynamically based on OCR info, if it is running
export ORACLE_SID=$($SRVCTL status instance -d $DBNAME -n `$HN -s`| \
$GREP ‘is running’ | $AWK ‘{print $2}’ )
logit info “ORACLE_SID is $ORACLE_SID”
### if there’s no SID defined locally or it isn’t running, stop
if [ -z “$ORACLE_SID” -a “$WALLET” = ‘false’ ]; then
logit error “No running ORACLE_SID available on this host, exiting”
exit 2
fi
### if using password-based startup, use this
if [ “$WALLET” = ‘false’ -a -n “$DBFS_PASSWD” ]; then
$RMF $DBFS_PWDFILE
if [ -f $DBFS_PWDFILE ]; then
logit error “please remove $DBFS_PWDFILE and try again”
exit 1
fi
$ECHO $DBFS_PASSWD > $DBFS_PWDFILE
logit info “spawning dbfs_client command using SID $ORACLE_SID”
(nohup $DBFS_CLIENT ${DBFS_USER}@ -o $MOUNT_OPTIONS \
$MOUNT_POINT < $DBFS_PWDFILE | $LOGGER -p ${LOGGER_FACILITY}.info 2>&1 & ) &
$RMF $DBFS_PWDFILE
elif [ “$WALLET” = true ]; then
### in this case, expect that the /etc/fstab entry is configured,
### just mount (assume ORACLE_SID is already set too)
logit info “doing mount $MOUNT_POINT using SID $ORACLE_SID with wallet now”
$MOUNT $MOUNT_POINT
fi
### allow time for the mount table update before checking it
$SLEEP 1
### set return code based on success of mountin
$SCRIPTPATH status > /dev/null 2>&1
if [ $? -eq 0 ]; then
logit info “Start — ONLINE”
exit 0
else
logit info “Start — OFFLINE”
exit 1
fi
;;
‘stop’)
$SCRIPTPATH status > /dev/null
if [ $? -eq 0 ]; then
logit info “unmounting DBFS from $MOUNT_POINT”
$FUSERMOUNT -u $MOUNT_POINT
$SCRIPTPATH status > /dev/null
if [ $? -eq 0 ]; then
logit error “Stop – stopped, but still mounted, error”
exit 1
else
logit info “Stop – stopped, now not mounted”
exit 0
fi
else
logit error “filesystem $MOUNT_POINT not currently mounted, no need to stop”
fi
;;
‘check’|’status’)
### check to see if it is mounted
$MOUNT | $GREP “${MOUNT_POINT} ” > /dev/null
if [ $? -eq 0 ]; then
logit debug “Check — ONLINE”
exit 0
else
logit debug “Check — OFFLINE”
exit 1
fi
;;
‘restart’)
logit info “restarting DBFS”
$SCRIPTPATH stop
$SLEEP 2
$SCRIPTPATH start
;;
‘clean’|’abort’)
logit info “cleaning up DBFS using fusermount and kill on dbfs_client and mount.dbfs”
$FUSERMOUNT -u $MOUNT_POINT
$SLEEP 1
$PS -ef | $GREP “$MOUNT_POINT ” | $GREP dbfs_client| $GREP -v grep | \
$AWK ‘{print $2}’ | $XARGS $KILL -9
$PS -ef | $GREP “$MOUNT_POINT ” | $GREP mount.dbfs | $GREP -v grep | \
$AWK ‘{print $2}’ | $XARGS $KILL -9
;;
*)
$ECHO “Usage: $SCRIPTNAME { start | stop | check | status | restart | clean | abort }”
;;
esac |